
Wpis archiwalny, oryginalnie pojawił się w Mój Mac Magazyn #3/2016

Muzyka. Świetna rzecz. Można ją słyszeć, czuć. Stymuluje emocje, wpływa na nasz nastrój. Pobudza lub uspokaja. Jednoczy lub dzieli. Pomaga znaleźć pokrewne dusze. Albo wrogów. Obnaża naszą osobowość, odzwierciedla wrażliwość lub zdradza niewybredne gusta. Jednak niezależnie od preferowanego gatunku, istotnym jej elementem jest jakość. Dynamika, ilość słyszalnych detali, spektrum dźwięków, smaczki, niuanse, przestrzeń otaczającej nas sceny – to wszystko ma kolosalne znaczenie. Od czego tak naprawdę zależy ta jakość? Na pewno od sprzętu, który wykorzystujemy do odsłuchu. Nie od dziś wiadomo, że tor reprodukcji dźwięku jest tak dobry, jak jego najsłabsze ogniwo. Dlatego nawet prosta modyfikacja, np. zmiana dołączanych do iPhone, iPoda lub innego grajka słuchawek, potrafi przynieść zaskakujący efekt i pozytywną zmianę. Nie każdego stać na inwestycje w sprzęt naprawdę wysokiej klasy, dlatego warto zastanowić się nad innymi sposobami poprawy odbioru ulubionych utworów.
Produkty z nadgryzionym jabłuszkiem nie mają powodu do wstydu. Zastosowane układy kart dźwiękowych, przetworniki cyfrowo-analogowe i inne komponenty, zdecydowanie nie reprezentują najniższej półki. Ale elementem, na który my – użytkownicy mamy wpływ, jest jakość materiału dźwiękowego. Nasze odbiorniki – uszy, to skomplikowany aparat absorbujący fale dźwiękowe w postaci analogowej, przekształcający je w drgania mechaniczne, a następnie w impulsy nerwowe. Analogowa natura dźwięku, to gwarancja maksymalnej wierności i szczegółowości informacji. Jednak obecnie konsumujemy muzykę w postaci cyfrowej, prostej do przechowywania, przetwarzania i odtwarzania przez komputery oraz inne urządzenia elektroniczne. Nie dość, że taka zdigitalizowana informacja zajmuje mniej miejsca, to jeszcze łatwo zachować jej powtarzalność przy kopiowaniu. Dystansując się do realizmu przekazu. Na szczęście (a może i nie?) słuch, podobnie jak i pozostałe nasze zmysły łatwo oszukać. Do tego właśnie sprowadza się często cyfrowa obróbka dźwięku.
Płyta audio CD (CD-DA), wynalazek opracowany przez koncerny Philips oraz Sony ma już prawie trzy i pół dekady. Muzyka przechowywana na takiej płycie, jest poddana konwersji z postaci analogowej na cyfrową, z wykorzystaniem tzw. kodowania PCM (Pulse Code Modulation) o częstotliwości próbkowania 44,1 kHz, z rozdzielczością 16 bitów na próbkę. Warto wyjaśnić skąd takie wartości, prawda? Badania naukowe wykazały, że pasmo słyszalnych przez człowieka częstotliwości mieści się w zakresie od 16 Hz do 20 000 Hz. W czasie, gdy określano specyfikację standardu CD-Audio, częstotliwość 44,1 kHz stosowano do cyfrowego zapisu ścieżek audio na taśmach wideo. Gdy podzielimy ją przez dwa, otrzymamy 22,05 kHz – jest to tzw. częstotliwość Nyquista spełniająca warunek odtworzenia sygnału bez zniekształceń. A skąd 16 bitów? Taka rozdzielczość oznacza, że każda próbka dźwięku o czasie trwania równym 1/44 100 części sekundy, może przybrać jedną z ponad sześćdziesięciu pięciu i pół tysiąca wartości w przedziale od -32 768 do +32 767. To również gwarancja uzyskania stosunku sygnału do szumu (SNR – Signal-to-Noise Ratio) na poziomie 96,33 dB. Pomimo faktu, że dla ludzkiego ucha parametr ten może osiągnąć nawet 130 dB, wartość stosowana w CD-Audio sprawdza się u znakomitej populacji słuchaczy. Zatem biorąc pod uwagę niedoskonałości ludzkiego narządu słuchu możemy przyjąć, że zapis cyfrowy z powyższymi parametrami zapewnia jakość audio, którą mało kto będzie w stanie odróżnić od oryginału. Gdy pomnożymy częstotliwość próbkowania 44 100 Hz przez rozdzielczość 16 bitów/próbkę oraz dwa kanały (dźwięk stereo), otrzymamy wartość 1 411,2 kbit/s (~1,4 Mbps) – określającą parametr zwany przepływnością. Do tego parametru, będącego miarą chwilowego natężenia strumienia danych, wrócimy dalej.
Największą wadą płyt audio CD jest ich stosunkowo niewielka pojemność. Jeden krążek jest w stanie pomieścić maksymalnie około 80 minut muzyki. Ponadto, na takim nośniku znajdziemy najczęściej pojedynczy album ulubionego artysty, trwający krócej… A przecież chcielibyśmy mieć całą swoją muzykę przy sobie, zawsze. Gotową, by zabrzmieć po naciśnięciu klawisza Play. Chęć upakowania większej ilości materiału na płycie, dysku lub w pamięci odtwarzacza, doprowadziła do opracowania wielu różnych formatów kompresji dźwięku. Formaty te możemy podzielić na stratne i bezstratne. Podstawową i najważniejszą różnicą między kompresją stratną a bezstratną jest to, że stosując tę ostatnią możemy powrócić do pierwotnej wersji danych, bez utraty jakiejkolwiek informacji.
Przykładem pierwszego typu jest najpopularniejszy format, a dokładniej algorytm kompresji dźwięku – MP3 (w zasadzie powinniśmy używać określenia MPEG-1/MPEG-2 Audio Layer 3). W przypadku tego formatu, stosuje się przepływność o wartości do 320 kbit/s. Jak widać, nawet przy wybraniu najłagodniejszych i najmniej rygorystycznych parametrów kompresji, plik wynikowy audio będzie około 4,4 raza mniejszy niż odpowiednik na kompakcie. I to bez zastosowanej dodatkowej kompresji bezstratnej, której poddawane są skompresowane dane przeanalizowanych pasm częstotliwościowych. Brzmi tajemniczo, więc dla analogii wyobraźcie sobie np. 10 zdjęć w formacie RAW, które poddajemy konwersji do JPEG, a następnie pakujemy je archiwizerem, np. ZIP. Po rozpakowaniu otrzymamy dokładnie te same 10 plików, ale żadnego z nich nie da się przywrócić do pierwotnej postaci (RAW). W praktyce często stosuje się niższy bitrate oraz mechanizm VBR – przepływności zmiennej. W rezultacie utwór skompresowany algorytmem MP3 może być znacząco mniejszy (nawet kilkunastokrotnie), przy zachowaniu akceptowalnej (nie dla wszystkich, rzecz jasna) jakości.
Dobrym przykładem formatu bezstratnego jest ALAC (Apple Lossless Audio Codec). Dzięki jego zastosowaniu zyskujemy mniej więcej od 40 do 60 % oszczędności miejsca, przy zachowaniu pełnej jakości źródłowych danych, oraz możliwości rekonstrukcji pierwotnej postaci. Przepływność w formacie Apple Lossless jest odpowiednio niższa od tej, którą oferuje zapis na płycie CD-Audio, co jednak nie ma wpływu na jakość. Zmniejszenie wielkości pliku następuje dzięki algorytmowi analizującemu nadmiarowość informacji, oraz m.in. użyciu mniejszej ilości bitów dla często występujących danych.
Poniżej przedstawiam porównanie wielkości tego samego albumu (Mike Oldfield – „Amarok”) w wersji nie skompresowanej, poddanego kompresji bezstratnej oraz stratnej:
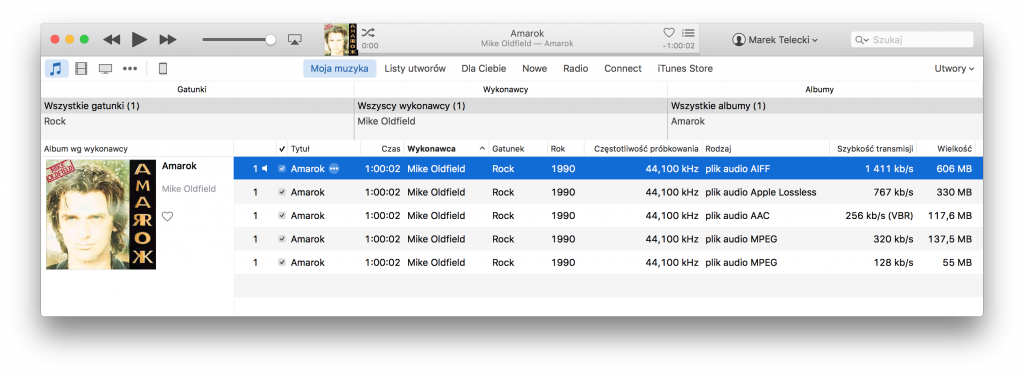
Widać, że godzinny materiał to nieco ponad 600 MB bez kompresji. Konwersja do skompresowanego formatu bezstratnego ALAC pozwoliła oszczędzić 45 %, dla formatu AAC+ zysk wyniósł już 80 %, dla MP3 przy najlepszych parametrach – 77 %, a dla swego czasu najbardziej popularnego ustawienia – prawie 91 %.
Powyższy, mało naukowy i obarczony sporymi uproszczeniami wywód (za co proszę o wybaczenie znawców tematu), ma za zadanie pomóc Czytelnikom w dobraniu właściwego formatu audio do konkretnych zastosowań. Na potrzeby strony WWW zastosujemy grafiki w gorszej jakości i niższej rozdzielczości, czego nie zrobimy w przypadku opracowywania materiału do druku, lub prezentacji na wielkoformatowym billboardzie. Podobnie, możemy pozwolić sobie na pewne kompromisy słuchając muzyki w terenie, podczas treningu, jazdy pociągiem. Możliwości przenośnych odtwarzaczy, okoliczności odsłuchu, nasze skupienie, czy raczej rozproszenie i inne aspekty, skutecznie tuszują niedoskonałości skompresowanego materiału. Przeciwnie, gdy delektujemy się ulubionym dziełem muzycznym w domowym zaciszu, korzystając z zaawansowanego sprzętu HiFi, wszelkie braki zostaną bezlitośnie uwypuklone i będą drażnić zmysł słuchu.
Istnieje wiele formatów stratnej kompresji dźwięku. Różnią się od siebie między innymi zastosowanym modelem psychoakustycznym, zakresem częstotliwości próbkowania, obsługiwaną liczbą kanałów, wydajnością – zarówno w kwestii wielkości pliku wynikowego, jak i potrzeb sprzętowych do realizacji dekompresji, oraz przeznaczeniem. Częstotliwości sygnału ludzkiej mowy zawierają się w zakresie od 300 Hz do 8 kHz, nie ma więc sensu zajmować się wartościami poza tym pasmem. Można tu zastosować dużo bardziej agresywną kompresję i otrzymać dane o stosunkowo niewielkim rozmiarze. Ale już w przypadku muzyki sprawa się komplikuje i rosną wymagania odnośnie zastosowanego algorytmu. Co więcej, znaczenie ma również gatunek muzyczny: utwory rockowe, metal, jazz czy muzykę klasyczną trudniej skompresować bez utraty dynamiki, szczegółów czy „powietrza”. Dużo mniej kapryśne są takie gatunki jak: pop, rap, hip-hop, disco, house i podobne. Należy o tym pamiętać, wybierając wyjściowy format audio i parametry kompresji.
Warto przyjrzeć się, jakie formaty wspierane są na platformie Apple. W przypadku komputerów nie ma to specjalnie znaczenia, bo dla systemu OS X znajdziemy programy zdolne odtworzyć nawet najbardziej egzotyczne formaty. Domyślnym „grajkiem” na Maczkach jest iTunes – program lubiany przez jednych i nienawidzony przez drugich. Bez dodatkowych zabiegów potrafi odtworzyć, zapisywać i konwertować pliki audio w następujących formatach:
a) Stratne:
- MP3
- AAC
b) Bezstratne:
- AIFF
- WAV
- ALAC
Jeśli to za mało, zawsze można wykorzystać systemowy QuickTime Player, uzbrojony na dokładkę w poszerzające możliwości wtyczki (plug-ins), jak np.: Telestream Flip4Mac, pozwalający na odtwarzanie plików w formacie WMA (Windows Media Audio).
Osobiście polecam odtwarzacz pod nazwą VOX, który zagra pliki w formatach, z którymi nawet nie miałem do czynienia: MP3, WAV, FLAC, AAC, M4A, MP1, MP2, MP4, APE, MPC, SD2, AIF, AIFF, OGG, SPX, TTA, SND, IT, XM, AY, GBS, GYM, KSS, SAP, VGM.
Większy problem dotyczy pozostałych produktów Apple, tzn. iPhone, iPad, iPod czy Apple TV. Zwłaszcza, gdy zapragniemy odtworzyć pliki dźwiękowe natywnie, z użyciem systemowych programów i usług. Wspólne dla tych urządzeń i „koszerne”, są następujące formaty audio: AAC (16 – 320 kbps), Protected AAC (pliki ze sklepu iTunes Store zabezpieczone DRM), HE-AAC (V1) – AAC+, MP3 (16 – 320 kbps), MP3 Variable Bit Rate, Audible (formaty 2, 3, 4), Apple Lossless, AIFF i WAV.
Co więc począć, gdy w nasze ręce trafi materiał skompresowany z użyciem kodeka, którego jabłuszka nie lubią? Skorzystać z konwertera. W Mac App Store jest wiele świetnych programów spełniających to zadanie. Darmowych jak i płatnych.

Osobiście od wielu lat korzystam z rewelacyjnego, X Lossless Decoder. Nawet bez zainstalowania dodatkowej biblioteki Libsndfile, potrafi „rozprawić się” z m.in. następującymi formatami:
- (Ogg) FLAC (.flac/.oga)
- Monkey’s Audio (.ape)
- Wavpack (.wv)
- TTA (.tta)
- Shorten (.shn) [tylko SHN v3]
- AIFF, WAV, itp.
Lista formatów wyjściowych jest równie obfita. Obsługa programu jest stosunkowo prosta mimo, że XLD udostępnia wiele zaawansowanych opcji, pozwalających na manipulowanie parametrami konwersji i kontrolę nad tym procesem.
Reasumując, jeśli chcemy zapewnić sobie relatywnie najlepsze doznania słuchowe, a przy tym możliwie najlepiej wykorzystać pamięć dyskową w mobilnych grajkach, warto przygotować swoją fonotekę w różnych formatach, adekwatnie do – nazwijmy to – miejsca, czasu oraz sposobu ich konsumpcji. Pewnym punktem odniesienia mogą być formaty i parametry audio w sklepach z muzyką online (np.: iTunes Store czy Google Music), oraz w serwisach streamingowych, np.: Spotify, Tidal, Deezer, czy Apple Music. Ten ostatni serwis stosuje kodek AAC+ (zwany również HE-AAC, High Efficiency Advanced Audio Codec), ze zmiennym bitrate do 256 kbps. Uważam jednak, że i tak najlepiej samemu przygotować testowy materiał, uwzględniający nasze muzyczne gusta i wykonać tzw. blind test – ocenić własnymi uszami, w jakim formacie i przy jakich ustawieniach utwory przestają brzmieć naturalnie.
Pamiętajmy, by nie popaść w skrajności. Priorytetem jest przyjemność słuchania, a na to większy wpływ ma odpowiedni repertuar, nie kilka herców czy bitów więcej. Audiofile i tak będą nami gardzić. Ostentacyjnie wydadzą absurdalnie duże pieniądze na metr kabla wygrzewanego w świetle księżyca, zarzekając się przy tym, że oni „słyszą ogromną różnicę”.

